当我把通过 vllm/toy_proxy_server.py 终于把 PD 分离跑起来以后,我开始有点嫌弃它了。这个小工具似乎有点太简单了,难道就没有更正式一点,”生产就绪“一点的网关能做这件事吗?我听说 llm-d 好像在这块做了一些事情,也许我可以去这里面寻求一些帮助。 但是当我开始了解这个项目时,我发现这件事好像没有那么简单······
Gateway API (Inference Extension)
LLM-D 的设计目标很奇怪,感觉是各种妥协后的产物。首先它不想动/重做传统的7层代理的基础设施——这些通过 Gateway API 和 基于之上的各种实现(我怀疑这个API就是同一波人搞的,他们不想打自己脸)。但是由于 OpenAI 这个协议本身是基于body来路由的,还有一些场景比如会根据KV Cache 来路由,这本身是和静态的 Gateway API 冲突的。于是想到基于 envoy 的 External Processing 来实现 AI 网关特有的一些逻辑,which is EPP(吐槽一句:这个EPP一会被解释成 External Processing Plugin,一会被解释成 End Point Picker),他们称这个为:
Community-aligned implementation using GIE and Envoy + External Processing (EPP) (基于GIE和Envoy+External Processing的社区导向的实现)1。
这个 Community-aligned implementation 意味着先抛开怎么做不谈,这套在原来的Gateway API及实现(只能是 Envoy based,例如istio,kgateway,GKE)上”扩展“,使其成为 Inference Gateway 的方法,让我们定义一个标准吧,which is GIE2。
这个缩写之前叫 GAIE,现在叫 GIE,经常能看到 llm-d 的文档里面混用。这篇文章里我统一用 GIE。
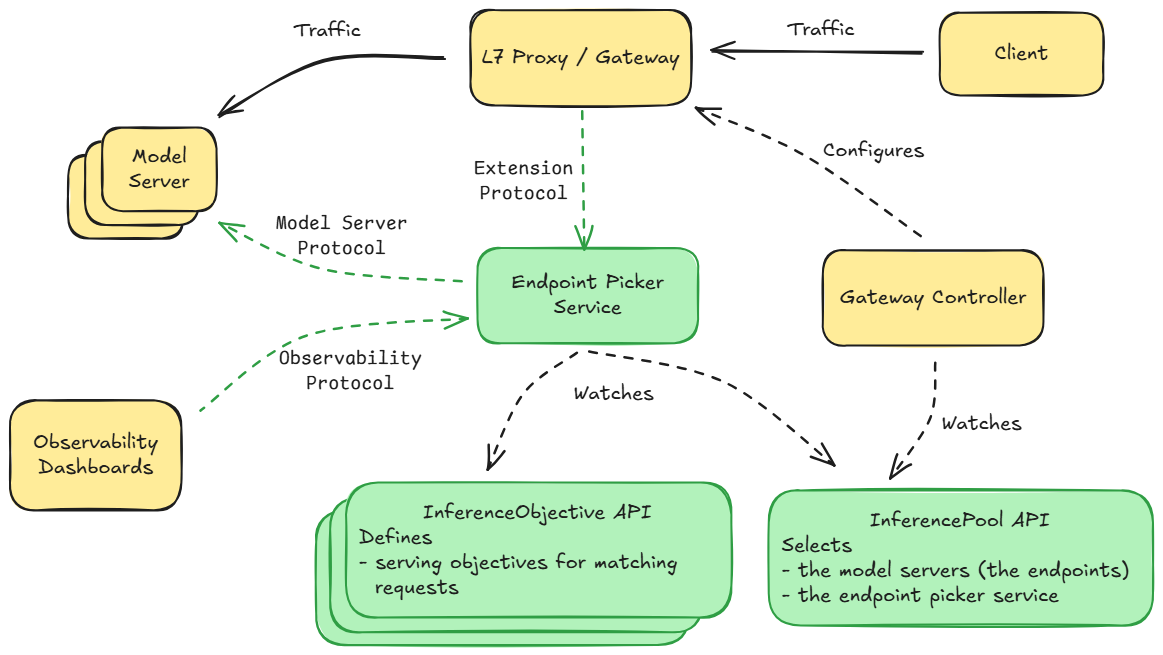
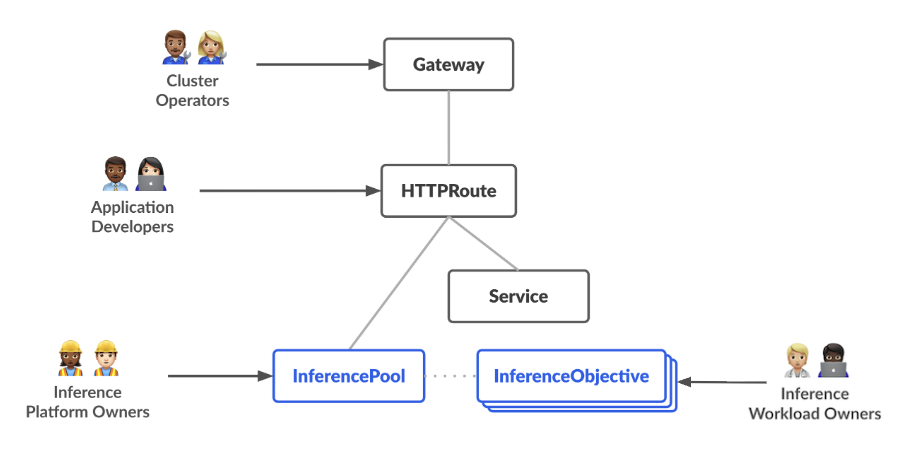
GIE 没有给 Gateway API 加新的东西,而是增加了 InferencePool 及其衍生的 InferenceObjective 两个API。InferencePool 可以看作AI Workload的 Service,用来选择一组运行推理服务的Pod。它和 Service 最大的不同是里面有一个 extensionRef 字段,用来指定 EPP3 。对于 Gateway API 的唯一侵入是: HTTPRoute 现在可以选择 InferencePool 为 backend。如下:
 图摘自:API Overview - Kubernetes Gateway API Inference Extension
图摘自:API Overview - Kubernetes Gateway API Inference Extension
说回EPP (Endpoint Picker),这个东西很奇怪,如果硬要类比的话它有点像Deployment——它不是一个固定的组件,而是一个满足某种实现的工作负载(就像所有的指标都暴露在 /metrics 端点并且符合Prometheus的格式一样),实现上它是一个集成了不同 Plugin 的组件的镜像,通过在 Config 里面配置来选择开启不同的组件,如下是一个 Chart 中的配置:
pluginsCustomConfig:
precise-prefix-cache-config.yaml: |
apiVersion: inference.networking.x-k8s.io/v1alpha1
kind: EndpointPickerConfig
plugins:
- type: single-profile-handler
- type: precise-prefix-cache-scorer
parameters:
indexerConfig:
tokenProcessorConfig:
blockSize: 64
hashSeed: "42"
tokenizersPoolConfig:
hf:
tokenizersCacheDir: "/tmp/tokenizers"
- type: kv-cache-utilization-scorer
- type: queue-scorer
- type: max-score-picker
schedulingProfiles:
- name: default
plugins:
- pluginRef: precise-prefix-cache-scorer
weight: 3.0
- pluginRef: kv-cache-utilization-scorer
weight: 2.0
- pluginRef: queue-scorer
weight: 2.0
- pluginRef: max-score-picker更多的插件和配置可以参考:Configuring the EndPoint Picker via configuration YAML file - Kubernetes Gateway API Inference Extension 按照 llm-d Inference Scheduler 的说法4,当满足下列条件时插件应该优先被提交到 GIE 的代码仓库:
- 它已经足够成熟,并已被证明具有广泛的适用性和实用性;
- 它可以单独在 EPP 中实现(即,llm-d 提供了一个完整的推理框架,而不仅仅是调度)。 换句话说,GIE 里的插件是EPP的 in tree,而在 llm-d/llm-d-inference-scheduler 里的代码,一方面 import 了 GIE 的 pkg,另一方面自己实现了一些插件来满足一些更高阶的场景,比如 PD分离。
 图摘自:gateway-api-inference-extension/pkg/epp at main · kubernetes-sigs/gateway-api-inference-extension · GitHub
当然你也可以有自己的实现,然后构建出自己的镜像,作为EPP部署上去。
图摘自:gateway-api-inference-extension/pkg/epp at main · kubernetes-sigs/gateway-api-inference-extension · GitHub
当然你也可以有自己的实现,然后构建出自己的镜像,作为EPP部署上去。
按理来说这个EPP的逻辑应该是可以在不同模型间复用的,但是现在的实现是一个 EPP 只能关联一个InferencePool。
让我们总结一下,GIE(Gateway API Ineference Extension) 的作用主要有3块:
- 定义了对gateway api的具体的扩展方式;
- 定义了两个新的CRD;
- 提供一个扩展(EPP)的默认实现;
最后一个问题,到底是谁在 Watch InferencePool? 看上面的图一个是EPP,另一个是 gateway。从 Istio 1.275 和 Kgateway v2.0.0 6开始,这两个 Gateway API 的实现开始支持这个CRD,下面是PR:
- Inference: Replaces InferencePool v1alpha2 with v1 by danehans · Pull Request #11965 · kgateway-dev/kgateway · GitHub
- feat(gw-inference): Replaces InferencePool v1alpha2 with v1.0.0-rc.1 by danehans · Pull Request #57295 · istio/istio · GitHub
这也解释了具体的控制流——Gateway Controller 通过 Watch Gateway、HTTPRoute 和 InferencePool 决定请求的路由策略,当新的请求进来时通过 External Processing 转发到 InferencePool 指定的 EPP,EPP 根据其他组件(包括sidecar、metrics等)收集的信息以及InferencePool selector 信息来决定将该请求路由到具体哪个Pod。
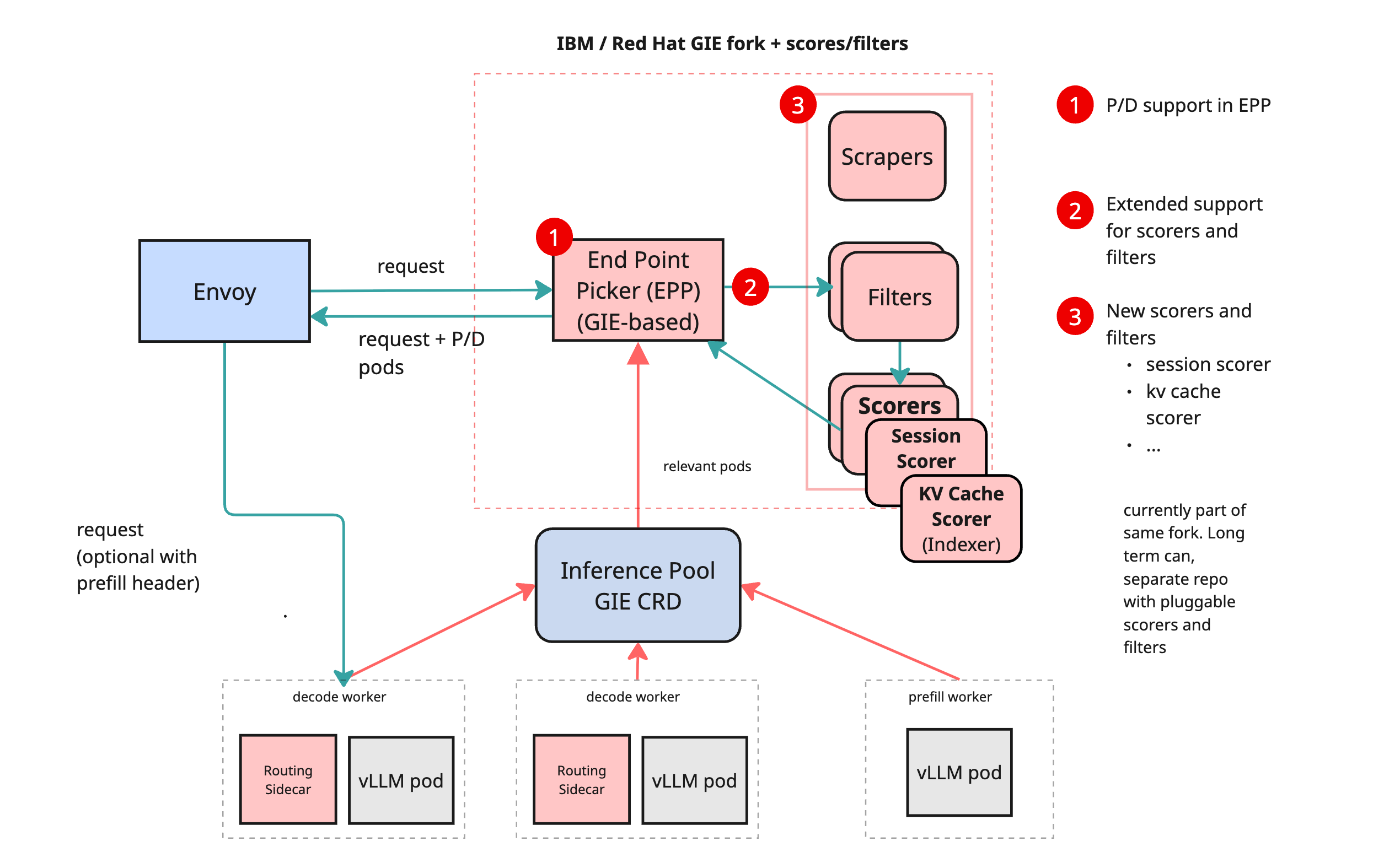 图摘自:LLM-D:分布式推理架构介绍(一) | samzong
图摘自:LLM-D:分布式推理架构介绍(一) | samzong
是时候部署模型了
在搭建了网关之后,接下来要做的就是部署模型服务了。与 Dynamo 的做法不同(ai-dynamo/grove),llm-d 并没有抽象一个 CRD 出来简化部署的逻辑,大概是觉得:
- 这个事情会很琐碎:对于不同的推理引擎(vllm/sglang/triton)有大量的的参数需要适配,如果只是通过 args 来传递好像又抽象能力不够,没有降低复杂度。此外,所有配置,例如张量/管道/专家/数据并行性、缓存策略、节点放置和 LoRA 组合——都与模型和硬件高度相关7;
- 如果只是在调度层面改进,已经有很多实现了,例如Valcano,LeaderWorkerSet,Kueue;
- 会和已经部署的工作负载冲突,这和 argo-rollouts 为了支持对工作负载灰度发布而定义
RolloutCRD的问题相同;
所以最终 llm-d ModelService 的形态就是一个Helm Chart,听起来是不是很可笑?和 LMCache 的 Production Stack 解决思路是一样的。 不过它在Proposal里也说了,只是作为研究和教学,并非旨在作为 llm-d 的生产级模型部署解决方案,也不提供高级编排和生命周期功能。
另外注意,这个 chart 可不会帮你创建模型服务需要的 InferencePool 和 HTTPRoute,你需要自己创建,或者使用 GAIE 的 Chart ,并且保证端口和label能对得上。
毕竟,在 GIE 的故事里,他们是三拨人:
总结
让我们总结一下,如果想要使用 llm-d 把模型服务管理起来要多少个服务和资源,我们从下往上看(我把 k8s资源用等宽字体表示):
- 部署模型:这块和之前一样,
Deployment或者LWS,当然也可以增加PodMonitor、PVC(提前下载好的模型权重),按照你的需要来选择,丰俭由人;- 如果想玩 PD 分离,还需要部署一个sidecar llm-d/llm-d-routing-sidecar
- EPP(Endpoint Picker):如果希望网关层能感知到模型服务的状态来路由,例如空闲程度、kv cache等,我们需要使用
InferencePool+ EPP 来实现,EPP 的部署形态是Deployment+Service,其镜像可以是 GIE repo 构建的 us-central1-docker.pkg.dev/k8s-staging-images/gateway-api-inference-extension 也可以是 llm-d-inference-scheulder 的 ghcr.io/llm-d/llm-d-inference-scheduler ; - 路由策略:创建
HTTPRoute,保证请求被路由到 InferencePool; - 网关:如果已经有了 Gateway Provider可以跳过,但需要保证是支持 GIE 的。如果没有这里有一个列表可供选择,我建议用 kgateway。部署完之后你还需要创建整个服务的入口,也就是一个
Gateway。
思考
在部署完上述所有组件之后我不禁思考,llm-d 为什么会是这样一种形态?我觉得原因有三个:
- 密涅瓦的猫头鹰在黄昏时起飞。现在依然是一个 AI技术快速更新和迭代的时期,无论推理引擎、大模型还是推理优化技术都在快速变化,在充满不确定之前,只有把产品做轻。事实也确实如此,从开始关注这个项目以来,整个架构包括代码仓库一直都在做很大的调整;
- 康威定理:设计系统的架构受制于产生这些设计的组织的沟通结构。llm-d 虽然是 RedHat 主导,但其实产生的过程和 k8s 社区 的 SIG Network,WG AI Gateway,WG Batching 都有很多交流,很多人都是重叠的(例如 Marcin Wielgus,Shane Utt ,Abdullah Gharaibeh),所以倾向复用和组合现有技术,相反 Nvidia 的 Dynamo 基本就是推倒一切全部重来;
- 软件的核心设计目标不是性能或易用,这一点在 ModelService 的Proposal和 GIE 的设计上都能看到。通过 Ext-Proc 的方式网关性能势必会差,但是有什么关系呢?相比于一个请求动辄几百ms~几十s的E2EL,请求在网关层耽误的几ms真的不值一提。使用Chart 的方式去部署大模型很难用,但是有什么关系呢?在硬件成本面前,模型部署就是成了一项手工业活动,没有高频率的CICD,而是一个团队围绕模型部署方案不断优化和打磨。这种背景下这么实现虽然难用,但是没有问题;
这些思考又把我指向了一个答案:llm-d 不是最终解决方案,在云原生上部署大模型还有长的路要走。
附录
llm-d Repo
llm-d 现在主要有两个 org,一个是 llm-d,一个是 llm-d-incubation
| Repo | 说明 |
|---|---|
| llm-d | 现在只有一些文档教程,配合 Blog 的 Well-lit Path |
| llm-d-infra | Chart,配置了运行 llm-d 的 k8s 基础组件 |
| llm-d-inference-scheduler | 根据负载、KV 命中、PD 分离感知进行调度的调度器 (GAIE 加强版以及下游) |
| llm-d-kv-cache-manager | KV 缓存管理器,作为库被 inference scheduler 引用 |
| llm-d-routing-sidecar | 为了支持 PD 分离而需要的Sidecar,现已被移到 inference scheduler |
| llm-d-model-service | 使用 Chart 帮助你部署模型服务 |
| workload-variant-autoscaler | 分布式推理工作负载的自动扩展器 |
| llm-d-inference-sim | 一个轻量级的vLLM模拟器 |
| llm-d-fast-model-actuation | 实验性质,快速启动模型 |
Footnotes
-
llm-d-inference-scheduler/docs/architecture.md at main · llm-d/llm-d-inference-scheduler · GitHub ↩
-
gateway-api-inference-extension/pkg/epp at main · kubernetes-sigs/gateway-api-inference-extension · GitHub ↩
-
Istio / Bringing AI-Aware Traffic Management to Istio: Gateway API Inference Extension Support ↩
-
Deep Dive into the Gateway API Inference Extension – kgateway ↩