前言
3Blue1Brown大神的视频 【官方双语】直观解释注意力机制,Transformer的核心 | 【深度学习第6章】 对 Transformer 的 Attention 机制做了非常直观的解释,看了好几遍,总算是感觉理解了一点。
为什么要有注意力机制
首先为什么要有注意力机制。我们对于输入进行tokenize的时候,更多还是基于单个的词语,即word embedding词向量,然而不同的词在不同的上下文中含义完全不一样,既有词意的(如 language model 和 fashion model)也有语意的(如 eiffel tower 和 miniature eiffel tower)。 所以为了搞清每个词对应的含义到底是哪个,就必须查询上下文,而上下文也不是每个词(token)对于 model/tower 的真正含义贡献是完全相同的,所以我们需要先找到真正会影响词意的那几个token,把注意力(attention)放到他们身上。Attention 这套机制就是做这个事情的。
公式解释
我们看看是如何实现的。下面是它的经典公式:
其中 Softmax 函数接受一个包含任意实数的输入向量,并将其转换为一个概率分布。输出向量的每个元素表示该类别的概率,且所有输出的总和为 1。 具体来说,给定一个包含 (n) 个元素的向量 ([z_1, z_2, …, z_n]),Softmax 函数的计算公式为:
Transformer 的整体架构如下,Attention 只是其中的一小块 building block。
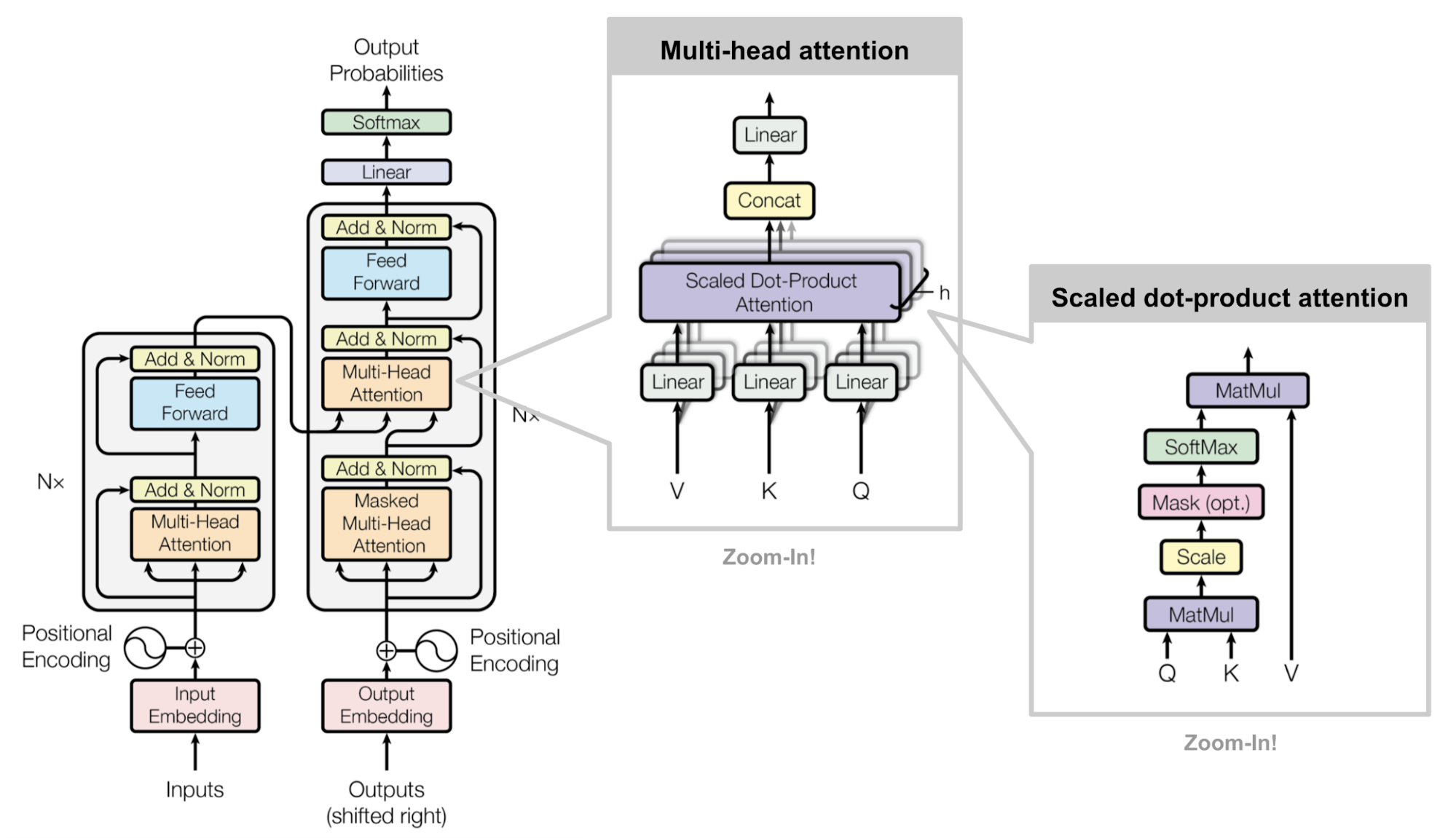
首先需要注意的是,表达式中的 Q、K、V 并不是三个固定的向量或者矩阵,他们是 、 和 三个矩阵和输入token的 embedding 序列相乘的结果。我们展开说说:
- 代表 embedding,是每个 token 的向量表示,一般来说维度越大,token 所对应的空间的复杂程度越高,比如GPT-3使用的词表是一个 50257 × 12288 的矩阵,其中 50257 是 vocab_size,即词表大小,12288 是每个embedding的维度,用 embedding_dim 表示。需要注意的是 embedding 还包含了token的位置信息;
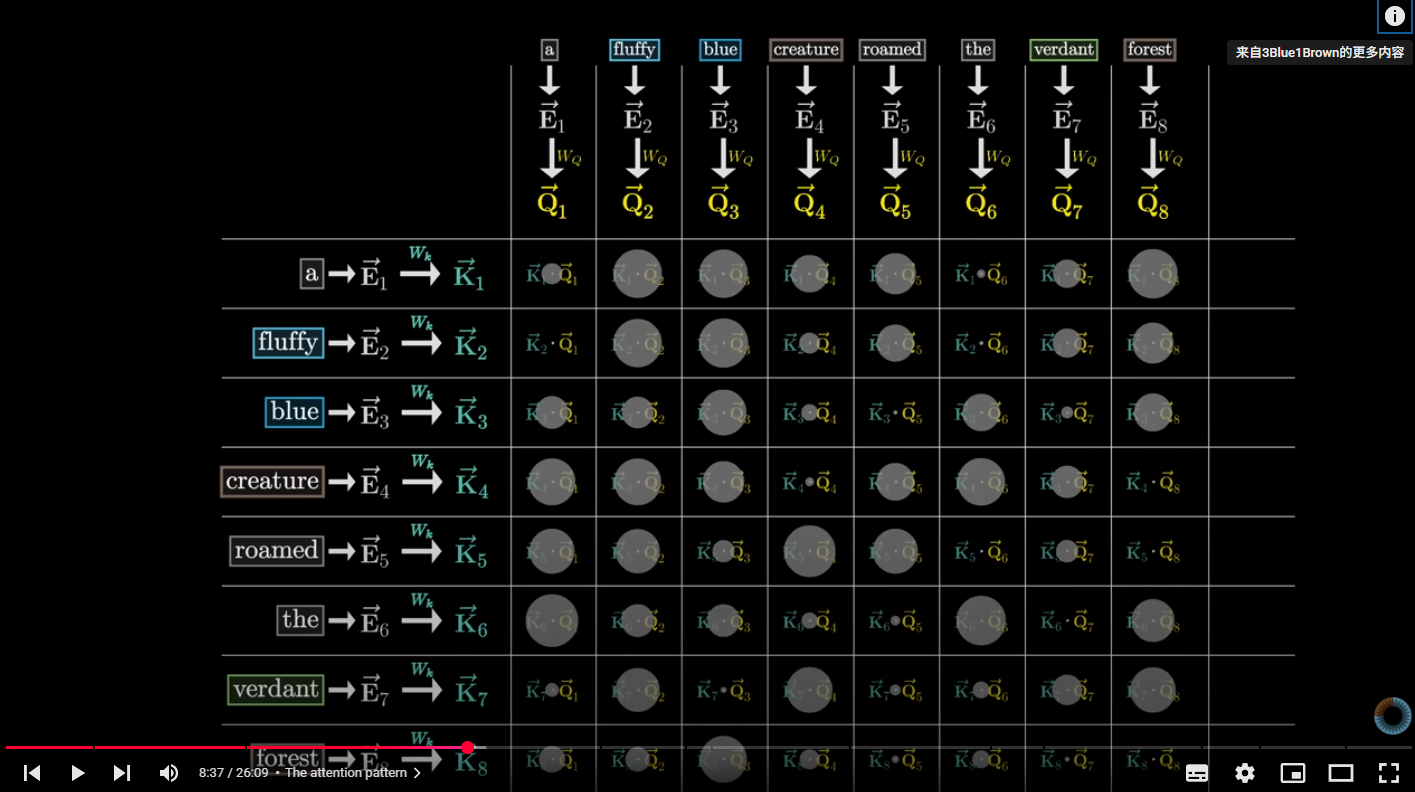
- 被称为 Query 向量,是 的结果,其中 是一个 head_dim x embedding_dim 的矩阵,head_dim 是这个Query 矩阵的维度,一般来说小的多,GPT-3里是128(这个128是如何确定的?后面会说明)直观点解释,通过和 相乘,Transformer 尝试找到一句话(数学上的表示即是一系列 构成的一个矩阵)里哪些是我们需要关注的部分,比如假设有个 Attention head 是要找到一句话中 名词的前置形容词对语义的影响, “a fluffy blue creature roamed the verdant forest“这句话它的 embedding 序列和 相乘即是将 所有词语 映射到一个较小的查询空间中(拥有128个维度),用向量来编码 这个embedding是否有前置形容词? 的概念;
- 被称为 Key 向量,它和 Q 类似,是 的结果,同样被映射到一个 128 维度的空间中,只不过这次编码的目的是 这个embedding是前置形容词 (就上面的例子来说)。当 K 和 Q 的方向对齐时(设想2个二维向量的夹角很小),就能认为他们相匹配。就本例而言, 会将 fluffy 和 blue 映射到与 creature 对应的Q相近的位置上。

为了衡量每个 和每个 的对齐程度,我们要计算所有 K-Q 对的点积,就像下面这个N * N的网格,其中点越大表示点积结果越大,相应地匹配程度越高。这个网格被称为 Attention Pattern。用机器学习的术语(lingo)来说,就是 fluffy 和 blue 的embedding attend to(注意到)creature 的embedding了。这个网格的大小是 (seq_len, seq_len),seq_len是指上下文的长度。
由于这个数值可能是从负无穷大到正无穷大的,所以需要使用 softmax 对其进行归一化。为了数值的稳定性,建议将所有点积除以 K-Q 对空间维度的平方根,也就是论文里面的
一个技术细节:训练的时候由于是对一段文本里面所有的token逐个进行计算,为了避免后词影响前词(比如 ”a fluffy blue creature roamed“ 影响到 ”a fluffy blue“ 的下一个token预测)所以会把计算结果矩阵中左下方的部分在 Softmax 之前置为 -Inf,这样之后就会变成0了。
由于 attention pattern 的大小等于上下文长度的平方,所以上下文长度会成为大模型的瓶颈。也因此出现了一些变体:Sparse Attentation Mechanism、Blockwise Attentation、Linformer、Reformer、Ring Attentation、Longformer、Adaptive Attentation Span……使上下文长度更具扩展性。
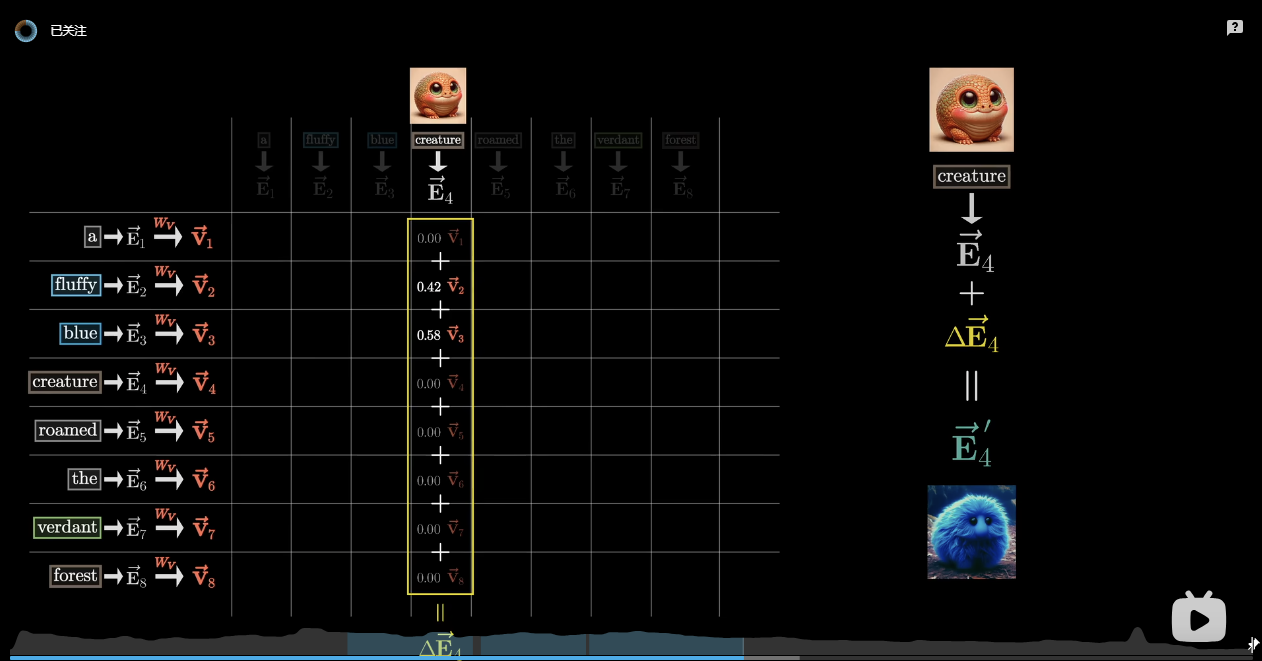
既然我们现在找到了哪些token是相关的,接下来要做的就是更新 embeddings,将各个词的信息传递给与之相关的词,比如你希望 fluffy 的embedding 能给 creature 的 embedding 带来某些变化,使其在 embedding_dim 这个空间里面的含义向另一个方向移动以更加靠近 ”fluffy creature“ 这个词对应的向量,Value矩阵 就是做这个的。
- Value向量是 和 的点积,但不同于 Q、K的是 是一个大小为 embedding_dim x embedding_dim 的矩阵,和 Attention Pattern 里面每个 K-Q 对的值作为权重求和(weighted sum)后,就是原来的 embedding 需要偏移的方向。
值矩阵的大小是 embedding_dim^2 ,但是实际上更为高效的做法是把它拆分成2个 head_dim x embedding_dim 的矩阵(这下和 、 一样大了)相乘。也就是 低秩分解 ,这里把它称为 (12288, 128) 和 (128, 12288)
![]()
与 self-attention 相对应的是 cross-attention(交叉注意力),用来处理诸如翻译、TTS这种两种embedding 之间的关联,与 self-attention 基本相同,只有 1. Key 和 Query 矩阵乘以的是不同的数据集,2. 因为不存在后值影响前值的问题,一般不会用到掩码。
到现在为止,都是在讨论 single head attention(姑且认为这个head主要是识别名词的前置形容词),完整 transformer 中每层通常由 multi-headed attention 组成,会有多个(Q, K, V)对,用来识别语义中的不同模式(例如语法、自然规律、民俗典故、甚至底层的科学原理等会影响到token含义的上下文),GPT-3中每层包含96个注意力头,而这样的多头注意力一共有96层,越靠后关注的语义逻辑可能更深(就像CNN中的不同层)。
另外一点需要注意的是,论文中或者实际的实现中,一般把 从每个头里面拆出来,连接成一个被称为 Output matrix 的矩阵,和每个 head 的结果连接后的矩阵相乘。
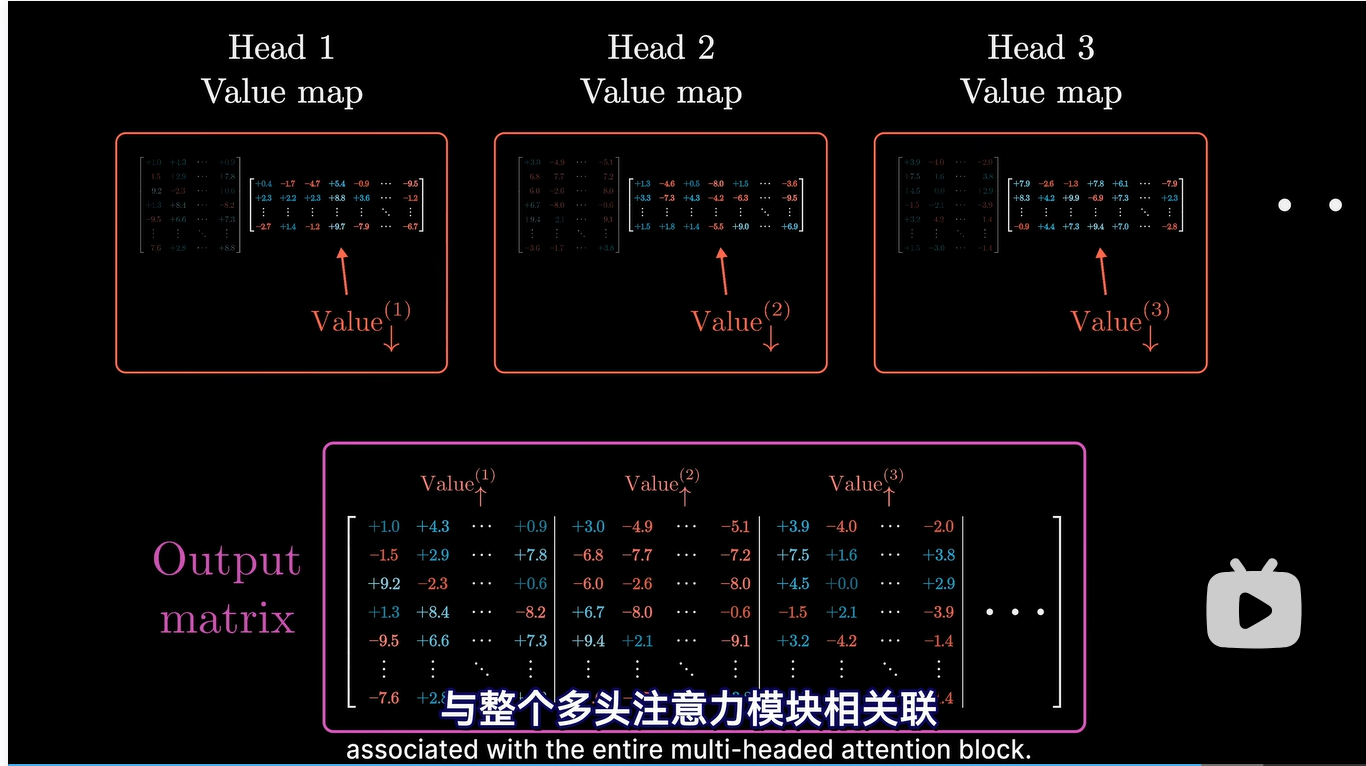
这里视频里面省略了,我做了一些更细节的推导。
假设上下文的长度 seq_len 是 1000,经过 计算后每个 head 里面的 attention pattern的大小是 (1000, 1000), 后的 大小是 (128, 1000)。
现在对这两个矩阵相乘(加权求和)后,大小是 (128, 1000),将96个头的结果纵向串联在一起,这个矩阵大小成了 (12288, 1000) 我们称为 Input Matrix,而下面的Output matrix大小是 (12288, 128 * 96) 。
我们将这两个矩阵做点积,得到的大小是 (12288, 1000),正好和输入的embedding序列一样大。这也解释了为什么 K/V/Q 的维度是128,其实只要保证 head_dim * n_head 等于 n_embedding,这两个取值可以任意。
参数量
最后我们回顾下 Transformer GPT-3 里 Attention 相关的参数量:
| 类型 | 参数量 |
|---|---|
| Embedding | d_embed 12,288 * n_vocab 50,527 = 617,558,016 |
| Key | d_key 128 * d_embed 12,288 * n_heads 96 * n_layers 96 = 14,495,514,624 |
| Query | d_query 128 * d_embed 12,288 * n_heads * n_layers 96 = 14,495,514,624 |
| d_value 128 * d_embed 12,288 * n_heads 96 * n_layers 96 = 14,495,514,624 | |
| d_embed 12,288 * d_value 128 * n_heads 96 * n_layers 96 = 14,495,514,624 | |
| 其他 | … |