什么是NVFP4
NVFP4 是 Nvidia 随着 Blackwell 架构的GPU推出的一种新的量化格式,相当于只用4 bit来存每个权重或/和激活值。
并且不可思议的是,在 NVIDIA 官方的精度基准测试中,将 DeepSeek-R1-0528 模型从 FP8 量化为 NVFP4 后,在七项评估任务中几乎没有性能下降1:
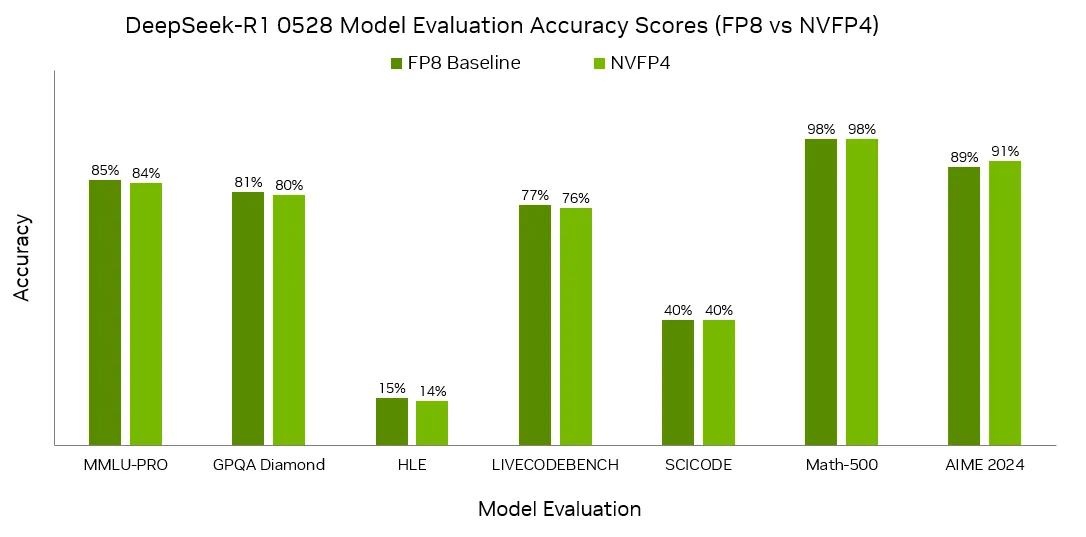 那么代价是什么呢,
那么代价是什么呢,古尔丹?
缩放因子
在开始介绍 NVFP4 之前我们需要先引入一个概念:缩放因子 scaling factor。常规的量化就是把一个精度更高(例如 FP16)的数向下等比例缩放到一个低精度下(例如 FP8)的值。加入了技能的量化
例如对于一个 FP16 可表示值的近似范围为 ,而一个 E4M3 的 FP8 ,最大值和最小值都确定了,那么缩放因子 就是 65504/240 。在实际的量化场景中,由于权重和激活值不是总是分布在 这么大的范围,我们完全可以根据每一层的权重/激活的取值分布(例如某一层权重取值在 之间)来定义一个缩放因子,这样我们有足够的空间来表示其他值之间的差距了,在缩放的时候对于精度的损失也会相对来说更低一些。
但如果原始的取值是(-1, 0, 9998, 9999, 10000)这种,那将这些值映射到取值范围在 [-10, 10] 的精度时就会显得右边特别拥挤,丢失了很多精度。因此有 非对称量化。非对称量化除了定义 缩放因子 还定义了零点 ,给出公式2:
其中 表示量化表示的范围。这个公式看着复杂,其实就是按因子缩放后再左右平移。
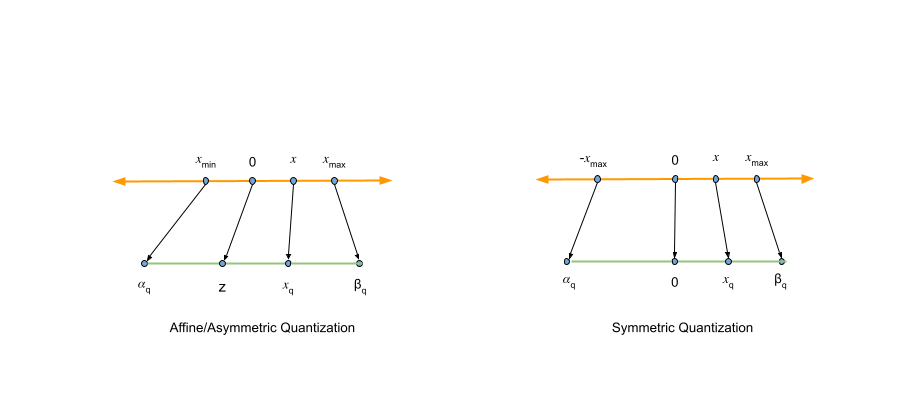 NVFP4 使用的是对称量化,which means 不需要存 这个参数。
NVFP4 使用的是对称量化,which means 不需要存 这个参数。
只有16个数字的世界
FP4 只有2个指数位和1个尾数位,可表示的正数只有 (0, 0.5, 1.0, 1.5, 2.0, 3.0, 4.0, 6.0) 8个(为了表示更多位去掉了Inf)3 。这么小的表示范围只能在采样个数上做文章了。
MXFP4 就是每32个值为一组,共享一个缩放因子,这个 是一个 8 bit 的指数表示,这是一个 UE8M0 的类型,意味着它能表示的缩放范围是 (刨除掉0后)。
NVFP4 在上面做的改进一个是采用了两阶段缩放,即先将 16个值编为一组(更小的编组意味着量化后丢失的精度更少),采用 E4M3的FP8 类型的数做为共享的缩放因子(E4M3 相比 E8M0 可以表示的浮点数更”细“,比如可以表示像0.75, 3.2 这种小数,但是范围更小——最大整数为 240,计算量也更大)。然后再对整个 Tensor 做一次量化,这个缩放因子采用 E8M23 的FP32的类型。
 (上图是反量化的过程,其实在做量化的时候应该反过来,先对 Tensor 做缩放再对每16个值元素做)
(上图是反量化的过程,其实在做量化的时候应该反过来,先对 Tensor 做缩放再对每16个值元素做)
下表给出了三种结构的区别1
| 特征 | FP4 ( E2M1) | MXFP4 | NVFP4 |
|---|---|---|---|
| 格式 结构 | 4 位 ( 1 个符号、2 个指数、1 个尾数) 加软件 scaling factor | 4 位 ( 1 个符号、2 个指数、1 个尾数) ,每 32 个值块 1 个共享的 power-of-two 尺度 | 4 位 ( 1 个符号,2 个指数,1 个尾数) 加 1 个共享 FP8 刻度 (每个 16 个值块) |
| 加速硬件扩展 | 否 | 是 | 是 |
| 显存 | 约 25% 的 FP16 | ||
| 准确性 | 与 FP8 相比,准确性有明显下降的风险 | 与 FP8 相比,准确性有明显下降的风险 | 降低准确率明显下降的风险,尤其是对于较大的模型 |
这里面的按 Tensor 和 按16/32 个元素量化就是量化粒度(Quantization Granularity)的选择。一般包括:Per-Tensor,Per-Channel 和 Per-Group,我把它粗暴地理解为每个矩阵、每一行或者每行里面多个值 共享一个缩放因子2。

更多的使用和验证的方法可以参考 4