背景
我们在 kubernetes 的环境中部署了容器化的 Jenkins,部署之初经常会出现OOM,经过一些调研和调整后,逐渐稳定起来。这个时候,又有同事发现Jenkins的内存用量一直在增长…
JVM
以下所有实验都是基于 JDK 17,不同版本支持的参数和行为会有所区别。
认识 JVM
和平常我们部署在k8s环境中的容器化的Go、Python服务不同,Java 应用通过 JVM 来解释和执行,此外 JVM 由较强的内存管理的能力,可以直接限制应用可用的内存(-Xms和-Xmx),可以认为这本身就是一种“容器化”的能力,所以 Java 应用的容器化要考虑的因素必然更多。
那么 JVM 如何管理内存呢?哪些因素可能会导致应用内存不够而发生 Out of Memory (OOM) 呢?
参考下面这张图
 来源:Medium
来源:Medium
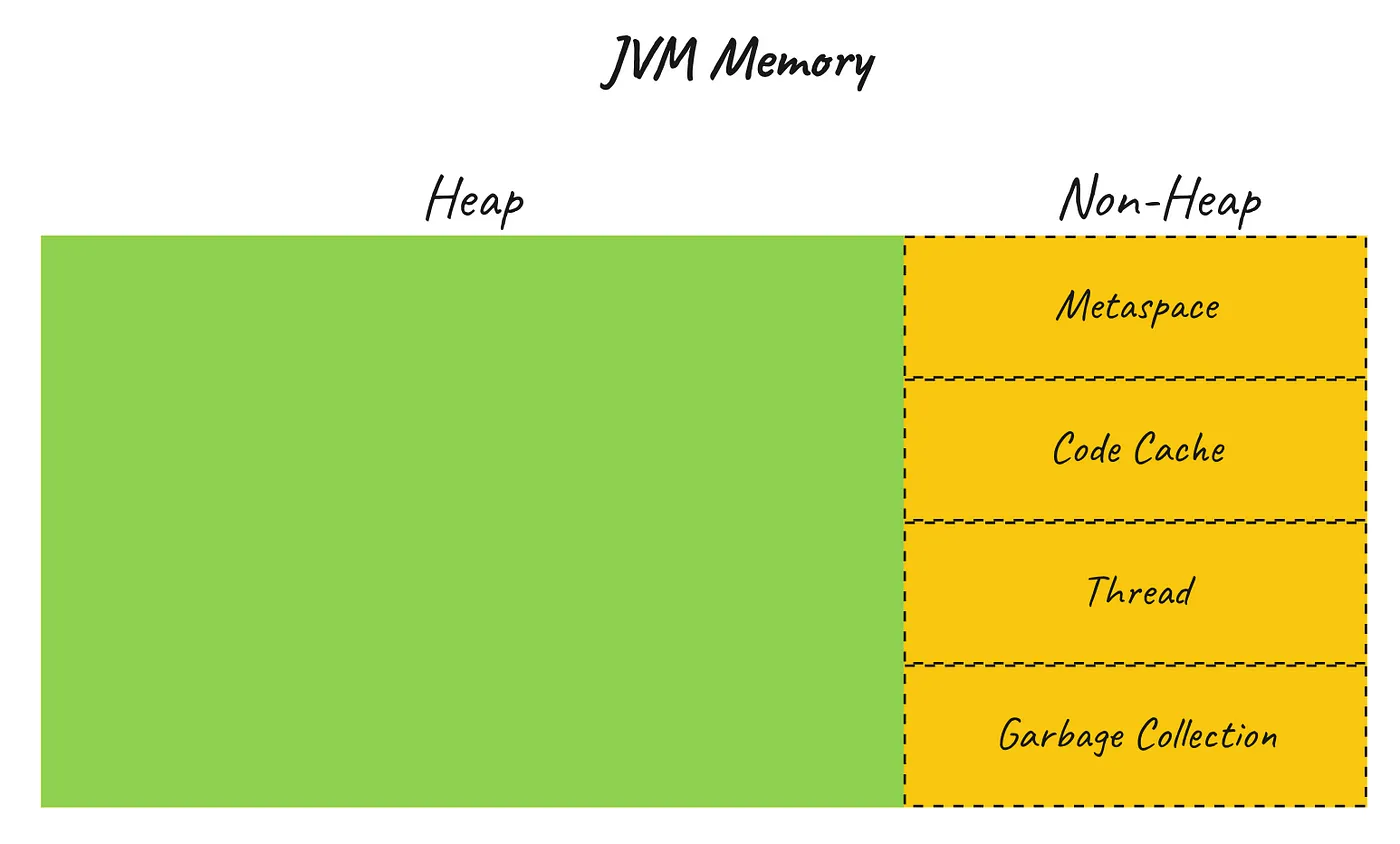
主要分为 Heap(堆) 和 Non-Heap 两部分。注意,这和我们常见的进程内存分配那张图里的 Heap 还不是一个东西(但是很像)。
 来源:
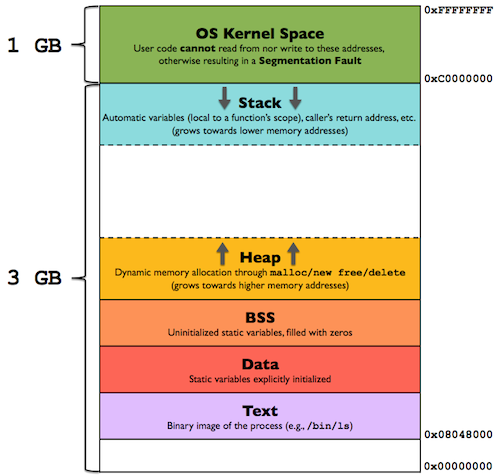
来源:上面那张图是JVM的内存管理模型,下面则是 Linux 进程的,本质上都是为了管理内存而进行的抽象,只是维度不同。
简而言之,对于 JVM,Non-Heap 这部分主要是存储元数据和代码结构体、方法,这部分区域大小比较固定,不太会成为 OOM 的元凶。而 Heap 用来存储Java程序创建的对象,直到对象被释放才会被GC回收占用的这部分内存,自然会随着应用服务的负载变化而变化,也是我们需要关注的重点。更多关于这两部分的解释可以参考 Java Memory 。
程序出现 OOM 的本质是由于运行需要更多内存,但是可分配的内存已经不够了——无论是由于 Heap 的增长超过了预先指定的大小(比如通过 -Xms4G 指定最大可用4G但实际上应用创建对象超过了4G),还是应用总的内存大小超过了机器或容器本身的内存限制(比如容器指定 memory limit 4G,Non-Heap 占用了500M,Heap 即使没有超过指定的大小也会导致 OOM,只不过这个 OOM 不是 JVM 而是 Kubelet 或者内核触发的), 这篇文章 有一个生动的例子帮助我们理解 OOM 产生的过程。
所以,想要避免程序出现 OOM 本质上还是要找到合适程序运行的堆和非堆内存大小。
观测
实践出真知
没人能完全预测程序运行时的状态,我们只有跑起来后从外部观测。
JVM 的工具箱中提供了很多工具方便我们进行观测和排查,我们一个个说。
内存追踪
我们第一个感兴趣的就是程序在运行的时候分配给不同区域的实际内存到底是多少,哪一部分是主要增长?
通过在启动程序的时候指定 JAVA_TOOL_OPTIONS
-XX:NativeMemoryTracking=detail我们可以在程序运行起来后执行
$ jcmd <pid> VM.native_memory summary查看内存分配。JVM 打印如下内容
Native Memory Tracking:
(Omitting categories weighting less than 1KB)
Total: reserved=3220660KB, committed=991708KB
malloc: 79580KB #957981
mmap: reserved=3141080KB, committed=912128KB
- Java Heap (reserved=1468416KB, committed=620544KB)
(mmap: reserved=1468416KB, committed=620544KB)
- Class (reserved=1053006KB, committed=23694KB)
(classes #26606)
( instance classes #25429, array classes #1177)
(malloc=4430KB #100197) (peak=4434KB #100148)
(mmap: reserved=1048576KB, committed=19264KB)
( Metadata: )
( reserved=131072KB, committed=127424KB)
( used=125628KB)
( waste=1796KB =1.41%)
( Class space:)
( reserved=1048576KB, committed=19264KB)
( used=17600KB)
( waste=1664KB =8.64%)
- Thread (reserved=158282KB, committed=23574KB)
(thread #156)
(stack: reserved=157832KB, committed=23124KB)
(malloc=271KB #936) (peak=292KB #1117)
(arena=180KB #308) (peak=2374KB #126)
- Code (reserved=253066KB, committed=71106KB)
(malloc=5378KB #22266) (at peak)
(mmap: reserved=247688KB, committed=65728KB)
...可以看到其中 Heap 保留内存 1.4G 左右,实际提交 620M;Non-Heap 中的 Class 保留1.1G,实际 23M。过一段时间我们可以再执行
$ jcmd <pid> VM.native_memory summary.diff来查看变化的部分。
通过针对性的压力测试和查看实际内存分配我们大致可以确定在不同的负载情况下,Heap 和 Non-Heap 分别设置多少内存大小合适。
GC
如果内存持续增长,无论指定多少堆内存都会发生 OOM,那么很有可能是内存泄露或者GC有问题。
通过在启动程序的时候指定:
-verbose:gc
-Xlog:gc*:file=gc.log:time,level,tags-XX:+PrintGCDetails 和 -XX:+PrintGCDateStamps 已经在JDK 11+ 中不再支持
我们可以让 JVM 打印出 GC 相关的日志:
[4623.393s][info][gc] GC(131) Pause Young (Normal) (G1 Evacuation Pause) 529M->247M(606M) 85.014ms
[4644.924s][info][gc] GC(132) Pause Young (Normal) (G1 Evacuation Pause) 530M->246M(606M) 19.658ms
[4654.298s][info][gc] GC(133) Pause Young (Normal) (G1 Evacuation Pause) 531M->247M(606M) 87.869ms
[4671.213s][info][gc] GC(134) Pause Young (Normal) (G1 Evacuation Pause) 532M->247M(606M) 25.208ms基于这些日志我们可以确认 JVM 的GC是否正常,时间是否合理,也可以打印更详细的GC过程协助分析,包括 GC 的选择和参数的调优,这是更高级的话题了,Oracle上有一系列的文章讲得比我深入,这里只记录这次排查过程中接触到的一些皮毛:
总的来说,垃圾收集器的设计是为了满足两个目标:最大暂停时间(Maximum Pause-Time)和吞吐量(Throughput)。前者是指GC在单次回收内存的时候暂停应用的最大时长,这影响了服务的响应延迟,后者反应了垃圾回收花费的总时长在总的运行时长中的占比,这影响了服务本身的吞吐量。这两个因素几乎总是相互制约的,如果想要单次暂停时长尽可能小,那么就需要尽量频繁地运行GC;如果希望GC的频次过高,那么就可能导致提供给业务的CPU时间片降低。不同的GC的实现基本就是在这两者之间做平衡。
需要注意的是,一旦上述两个目标满足指定阈值(通过 -XX:MaxGCPauseMillis=<nnn> 和 -XX:GCTimeRatio=nnn 指定),JVM 就会减小堆内存的大小直到某一条件不满足,对应地,也会增加堆内存(后面要考)。
JVM 提供了多种垃圾收集器的实现,基本就是这一光谱上的不同位置(表格由ChatGPT生成,我没有逐个核对):
| 收集器 | 类型 | 停顿特点 | 适合堆大小 | 吞吐量 | 适用场景 | 备注 |
|---|---|---|---|---|---|---|
| Parallel (吞吐量 GC) | 多线程 | 全停顿(STW),多线程 GC | 中堆(几GB) | 高 | 追求吞吐量的批处理、大数据应用 | 默认 GC(JDK8) |
| CMS (Concurrent Mark Sweep) | 并发+多线程 | 大部分并发,标记阶段短暂停 | 中到大堆(几GB) | 中高 | Web服务、延迟敏感应用 | 已被 G1 取代,不再维护(JDK 14 移除) |
| G1 (Garbage First) | 区域式+并发 | 小停顿,可配置最大停顿时间 | 大堆(>4GB) | 中高 | 大型应用,需要稳定响应时间 | JDK9+默认 |
| Shenandoah | 并发+低延迟 | 停顿极短(1-10ms) | 大堆(GB~TB) | 中 | 极端低延迟应用,如金融交易系统 | Red Hat 支持,JDK17+正式版,部分LTS版本 |
| ZGC | 并发+超低延迟 | 停顿极短(<1ms) | 巨大堆(几十GB~TB) | 中 | 超大堆,要求极低延迟系统 | Oracle 主导,JDK11+ |
结论是大部分现代应用的场景使用 G1GC 就足够应付。如果需要针对应用进行更细致的参数调优可以参考这篇。
指标
在第一次对 JVM 参数进行压测和调优的时候掉入过一个误区:有同事观察到 Jenkins 的内存一直维持在比较高的水位线,没有预想的随着请求下降而释放和回收内存。

这是因为观测的指标是容器的内存用量,而这一指标体现的实际上是 JVM 声明的堆内存+非堆内存的大小之和,并非真实的用量。如上面所说,只有在满足一定条件后 JVM 才会向操作系统释放和申请内存空间,才能在指标中看到内存大小的调整。
要更直观地观察到这一变化有两种办法:
- 调整 GC 策略,更积极地释放和申请内存。比如参数
-XX:MinHeapFreeRatio=n -XX:MaxHeapFreeRatio=n可以通过根据空闲内存在堆内存中的最小和最大占比,来动态调节堆内存的大小。-XX:-ShrinkHeapInSteps可以关闭分步收缩堆内存,更加直观地展示内存变化。注意这些参数在实验的时候可以开启或调整以使指标更加真实地反应内存动态变化,但在生产环境中这只会使得 GC “瞎忙和”,导致程序的吞吐量下降或者最大暂停时长增加; - 使用 JVM 提供的指标。也许你的应用已经暴露了一些更加“真实”的指标,比如对于Jenkins来说,插件 Metrics 就暴露了
vm.memory.heap.usage和vm.memory.total.used等指标;如果是自己开发的应用,也可以通过 Spring Boot Actuator, Micrometer 或 JMX Exporter 来暴露;
装进箱子的盒子
某种意义上来说,在容器里面跑 Java 应用就像是把盒子装进箱子里。JDK10+ 支持并在Linux上默认开启 -XX:UseContainerSupport 这一参数,以允许 JVM 感知容器,并根据容器的 resources.limits/requsts 来调整启动参数,我们这里仅仅讨论内存,更详细的策略可以参考这篇。
简单来说,JVM 认为当前可用的内存判断主要依赖 spec.containers[].resources.limits.memory ,不受 requests 的影响。因此,如果我们设置 -XX:MaxRAMPercentage=70,resources.limits.memory=2G,那么 JVM 实际上会分配给应用的最大堆内存也就是 1.4G。其他的相关参数如下:
| JVM option | Replaces JVM option | Description | Default value |
|---|---|---|---|
-XX:InitialRAMPercentage | -XX:InitialRAMFraction | Percentage of real memory used for initial heap size | 1.5625 |
-XX:MaxRAMPercentage | -XX:MaxRAMFraction | Maximum percentage of real memory used for maximum heap size | 25 |
-XX:MinRAMPercentage | -XX:MinRAMFraction | Minimum percentage of real memory used for maximum heap size on systems with small physical memory | 50 |
-XX:ActiveProcessorCount | n/a | CPU count that the VM should use and report as active | n/a |
| 来源:developers.redhat.com |
是的,你没看错,最小堆默认值比最大堆默认值还大,所以这两个值最好要显式指定。此外 JVM 不考虑 requests 也会容易引发一个问题。
潜在问题
我们知道 Kubernetes 的调度策略是基于 requests 来计算和筛选节点,而非 limits 或 usage。如果节点部署的主要是 Java 应用并且 MaxRAMPercentage 设置得不合理,导致应用实际占用内存长期大于 requests,那么节点会更容易触发驱逐的动作,导致Pod被频繁重新调度。举个例子,当配置 Pod requests/limits 1G/2G,MaxRAMPercentage=70 时,那么 Pod 实际使用内存为 1.4G,而 Scheduler 认为该节点只使用了1G。
对于如何避免这个问题,我倾向于像这篇文章 说的,最好将 memory requests 和 limits 设置相同,除非经过观测你非常确信应用的堆内存会长期收缩在比较低的水平,这应该也属于 Java 应用容器化的特殊问题。
结论
经过一段时间的压测和观察,我们最终确定了以下配置(只列出了关键部分) :
apiVersion: apps/v1
kind: Deployment
metadata:
name: jenkins
spec:
spec:
containers:
- env:
- name: JAVA_TOOL_OPTIONS
value: -XX:+PrintFlagsFinal
-XX:MaxRAMPercentage=70.0
-XX:MinRAMPercentage=20.0
-XX:+UseStringDeduplication
-XX:+ParallelRefProcEnabled
-XX:+DisableExplicitGC
-XX:+HeapDumpOnOutOfMemoryError
name: jenkins-demo-jenkins
resources:
limits:
cpu: "2"
memory: 4Gi
requests:
cpu: "1"
memory: 4GiMemory Working Set (WSS)
在使用一段时间后,有业务反馈 Jenkins 内存不够,一直持续增大,都已经调整到 16G 了。第一反应是 GC 有问题,了解到他们流水线的特点主要是保存的制品文件特别大,每个接近 1G,并发在10条左右后,就开始了在测试环境复现。
测试环境果然出现了类似问题,内存开始持续增高,但是查看了 JVM 的堆内存指标(vm_memory_total_used)发现是正常,并且远小于上图里面的值(700MB vs 2.1GB)。

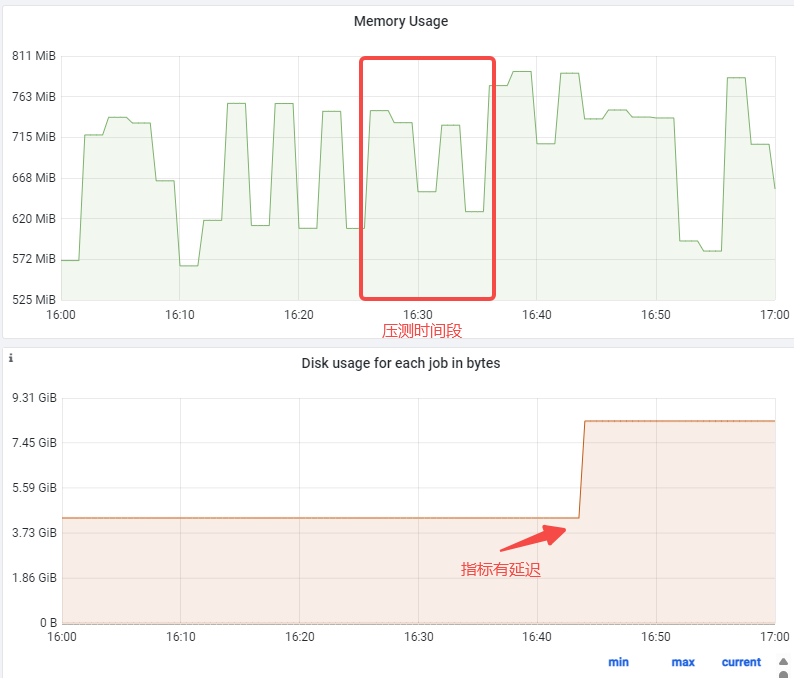
看来推高 Pod 内存用量的元凶另有其人。
认识 WSS
既然显示异常的指标是 pod_memory_working_set_bytes ,那我们先来认识一下它。
虽然 Java 应用申请和释放的内存是由 JVM 来管理,然而当涉及到的内存申请释放与内核相关时,便不再是JVM可以控制,让我们回顾一下 Linux 内核是如何划分内存的。
注意,在开始下面的内容之前我需要提醒一下,这里我们的视角发生了一次转变:刚才我们一直在从用户态,具体来说是 JVM 的视角来看待内存分配,接下来我们将切换到内核态,具体来说是 VM(Virtual Memory)的视角来理解内存在操作系统这一层面是如何分配和管理的。
我们知道VM主要有三个作用:
- 作为磁盘的缓存;
- 统一进程的内存地址,简化内存管理;
- 保护进程访问边界;
VM 通过页表(Page Table)来实现虚拟地址到物理地址的转换,所有的数据在 VM 的视角里都是页(Page),但是页根据作用可以分为两类:
Page Cache
作为文件缓存,通常是指从文件中读取到内存的那部分,用来加速文件从磁盘读取。相应地,写文件时也会先放置到 Page Cache 并标记为脏页,直到合适的时机被 flush 到磁盘上。这部分内存可以直接被回收。
Anonymous Memory
匿名内存是指不能以磁盘文件作为后备(file-backed cache)的那部分,一般被隐式地创建出来给进程的栈或者堆使用,或者是显式地调用system call mmap(2) 时创建。 这部分内存通常是进程可以访问的,当程序需要写内容时(这个写是指创建对象等内存操作)被创建并被标记为脏页,并在被回收的时候被换出(swapped out)。
关于为什么叫“匿名”内存:因为这部分内容的使用目的对于 Linux 内核来说完全是未知的(由应用决定),所以叫匿名,是不是和我们作为应用开发者的视角完全相反?
其他更细致的分类,比如 cat /proc/meminfo 时显示的结果就是这一基础上更细的划分和扩充,像Buffers和Cached都是属于 Page Cache , Active(file) + Inactive(file) + Shmem 也等于 Page Cache。需要更深入的学习可以参考这篇文章。
统计口径
回到我们的问题来,cAdvisor 暴露了一系列容器在linux内核层面的指标,比如:
- container_memory_usage_bytes,容器使用的总内存,这个指标由于包含 Page Cache 通常被认为是不太具有代表性的(因为它增高并不一定会诱发问题);
- container_memory_cache,容器文件读写产生的缓存,可以认为是 Page Cache;
- container_memory_rss,匿名内存+ swap 缓存,注意这不是我们常说的 RSS(Resident Set Size),RSS 还包含文件映射缓存(memory mapped file)。(一个问题:Kubernetes节点强制关闭 Swap ,那 swap 缓存不是永远是0吗?);
- container_memory_working_set_bytes,匿名内存+活跃的Page Cache,通常最接近应用最近使用的内存;
分析
有了以上背景知识我们再来看这个问题,可以很容易分析出来增长的那部分就是 Active Page Cache,把三个指标都展示出来确实如此:
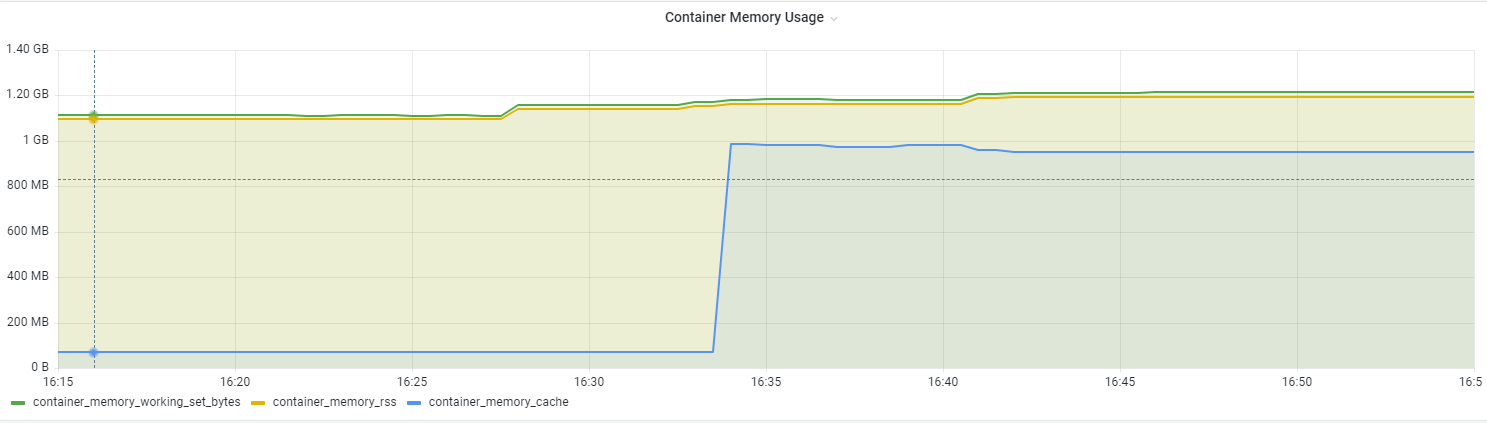
拉长时间线,我们可以看到这部分内存在逐渐减少,但是 working set size 却没有太大变化(甚至有增加)
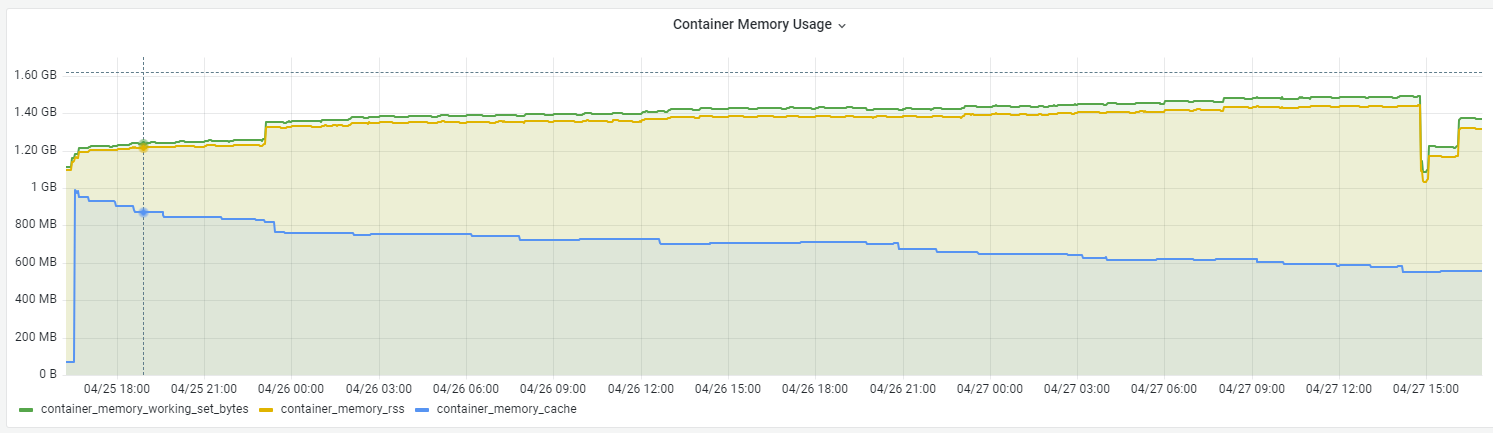
加入 JVM 相关的指标,可以看出增长的部分主要来自 JVM 的 heap committed,即向操作系统申请到的可被用来分配的内存大小:
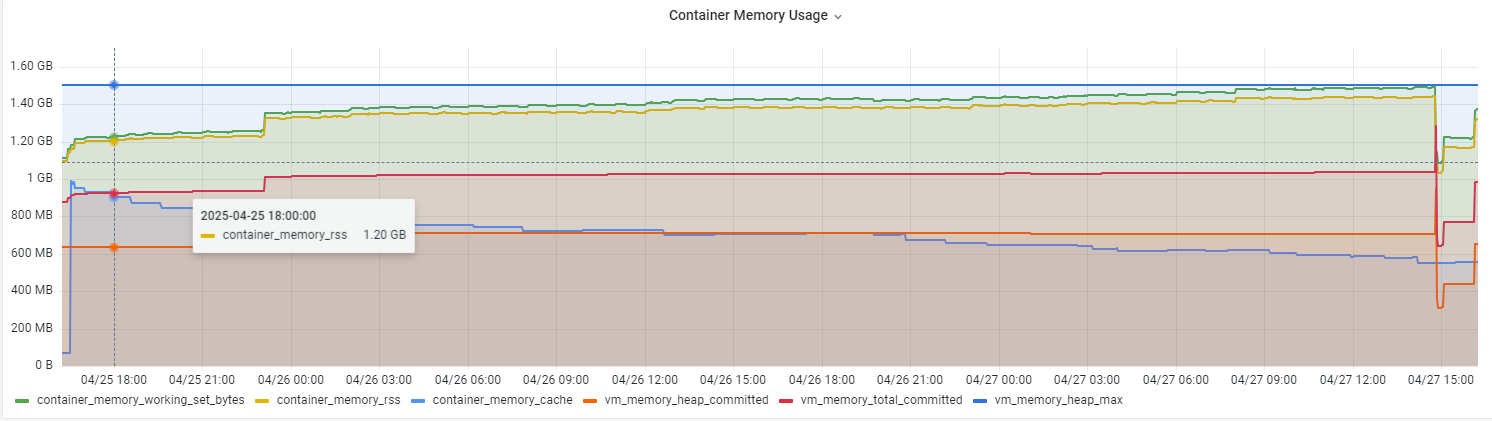
最有趣的是,当WSS一路增长到接近 vm_memory_heap_max 时触发了 JVM 的GC,内存被释放,WSS、heap committed 也开始随之下降。
关于为什么第一张图显示的 WSS 甚至超过了 Limits,是因为意外创建了2个
kube-prometh-kubeletService,导致指标求和后被double了 😰
优化
最后我们来讨论下,page cache 是否真的“安全”,不值得我们担心会导致应用OOM?
假设一种极端情况,短时间内 Jenkins 接收到了大量的大文件,但是磁盘IO的性能又跟不上,导致大量脏页产生,Page Cache 在内存中的占比不断提高。当程序需要申请匿名内存时,便会触发 Direct Reclaim ,让应用程序等待,直到内核成功回收足够的内存。但是假如由于严重的磁盘故障或者是 NFS网络问题,内核始终无法回收时,便会触发 OOM。
总的来说,Page Cache过高不会导致进程被OOM,上面这种场景一般通过监控 Buffers,Dirty Pages 或者是 IO wait 也能提前发现,这里 ChatGPT 整理了一张表,我感觉挺完整的:
| 观察指标 | 正常值 | 异常值(要警惕) |
|---|---|---|
| MemAvailable(/proc/meminfo) | >20%总内存 | <10%,严重警惕 |
| Buffers+Cached(/proc/meminfo) | 合理 | 占用 >30%总内存且 Available 少 |
| Dirty Pages(/proc/meminfo) | <1%总内存 | Dirty持续增长,说明回写卡 |
| vmstat wa (vmstat 1 5) | <5% | wa >10%,IO阻塞重 |
| blocked进程(b列)(vmstat 1 5) | 0 | 持续b>0,严重IO卡 |
| sar pgscan/pgsteal(sar -B 1 5) | 低 | 持续高,内存回收压力大 |
内核调优
如果服务器本身就是像 Jenkins 这种IO负载比较重,包含大量读写文件的场景,我们是否可以对其进行优化呢?
调 vm.dirty_background_ratio / vm.dirty_ratio
# 5%内存是脏页就开始后台同步,最多允许10%
sysctl -w vm.dirty_background_ratio=5
sysctl -w vm.dirty_ratio=10调高 vm.vfs_cache_pressure
# 默认100,调高意味着更积极回收inode/dentry cache
sysctl -w vm.vfs_cache_pressure=200加餐:内存回收流程
- 程序在申请新的内存(如
malloc(1GB))。 - 内核发现:当前空闲页(Free Pages)不足,没法直接满足。
- 内核就直接在申请内存的那个进程上下文里,开始做“回收”工作(reclaim):
- 回收 LRU 页(最近最少使用的内存页);
- 把脏页(dirty page)flush到磁盘;
- 释放 Page Cache;
- 释放 slab cache 等。
- 如果 reclaim 成功了,有了足够的 free pages,继续完成内存申请。
- 如果 reclaim 失败了(回收不到足够的页),可能会进入:
- Compaction(内存碎片整理)
- Direct Swap(如果有 swap,就往 swap 里扔)
- 触发 OOM Killer(内存真的不够,杀进程)
为什么叫 “Direct Reclaim”?
因为是直接在申请内存的进程里执行 reclaim 操作,不是系统后台(kswapd)慢慢异步做。而是”你想要内存,我内核直接让你等一下,我现在马上去找内存回来”。
所以 Direct Reclaim 期间,进程实际上是 阻塞(blocked) 的。
补充细节
| 点 | 说明 |
|---|---|
| 🧹 kswapd | Linux 有个后台内核线程 kswapd,会异步回收内存,正常情况下尽量靠它 |
| 🚨 Direct reclaim | 当 kswapd 来不及清理,才由应用自己触发 Direct Reclaim(同步回收,体验差) |
| 🧨 OOM killer | 如果 Direct Reclaim 也救不了,就触发 OOM Killer 杀掉一些进程释放内存 |
| ⏳ stall | Direct Reclaim 会导致程序 “alloc stalls”(分配卡顿),可以通过 vmstat、/proc/vmstat 看 pgalloc stall 统计 |
思考
这篇文章展示的内容不是一个短期的集中的过程,断断续续持续了一年,因为最近的一次业务问题才深度思考和研究了一把,结合之前的一些发现一起整理出来。最后我想说:
- 内存问题是一个系统性的问题,从应用程序到运行时到操作系统内核,再到云编排平台,每个环节都可能会导致服务工作不如预期;
- 可观测性是我们最大的帮手,而利用这些指标的前提是对系统充分的理解;
- 多输入,多输出,不会就问AI;
参考
- Factors Affecting Garbage Collection Performance
- Tricky Kubernetes memory management for Java applications
- Kubernetes学习(再谈kubernetes中的各种内存OOM)
- Kubernetes Container Memory Metrics | Baeldung on Ops
- Java业务容器后云原生监控中内存使用率高问题基本排查思路
- memory_working_set_size 是kubelet驱逐的指标
- How much is too much? The Linux OOMKiller and “used” memory
- 深入理解 Page Cache
- The /proc/meminfo File in Linux