前言
上一篇 3b1b 直观解释注意力机制笔记 里重新学习了Transformer里的注意力机制,其实我主要是想弄懂现在很火的 KV Cache 到底是什么原理,以及由此引申的一些新的技术比如 PD分离,LMCache 是什么。这篇文章就来系统地梳理下。
KVCache
我们重新回顾下 Attention 的那个公式:
我们说过表达式中的 Q、K、V 并不是三个固定的向量或者矩阵,他们是 、 和 三个矩阵和输入token的 embedding 构成的序列 的相乘的结果。这里面包含的计算步骤可以拆分成:
Transformer 的 decoder 过程就是对 不断执行上述过程以生成下一个 token ,再将新生成的 token的 embedding 加入后的 重新执行。
我们可以看到,对于步骤 1、2、4,完全可以省略掉 矩阵和 相乘的过程,而只计算 即可。
对于 3 也只需要把 和 逐个求点积后拼接到矩阵里,步骤5类似。
Transformers KV Caching Explained 有个动画非常生动地解释这一过程:
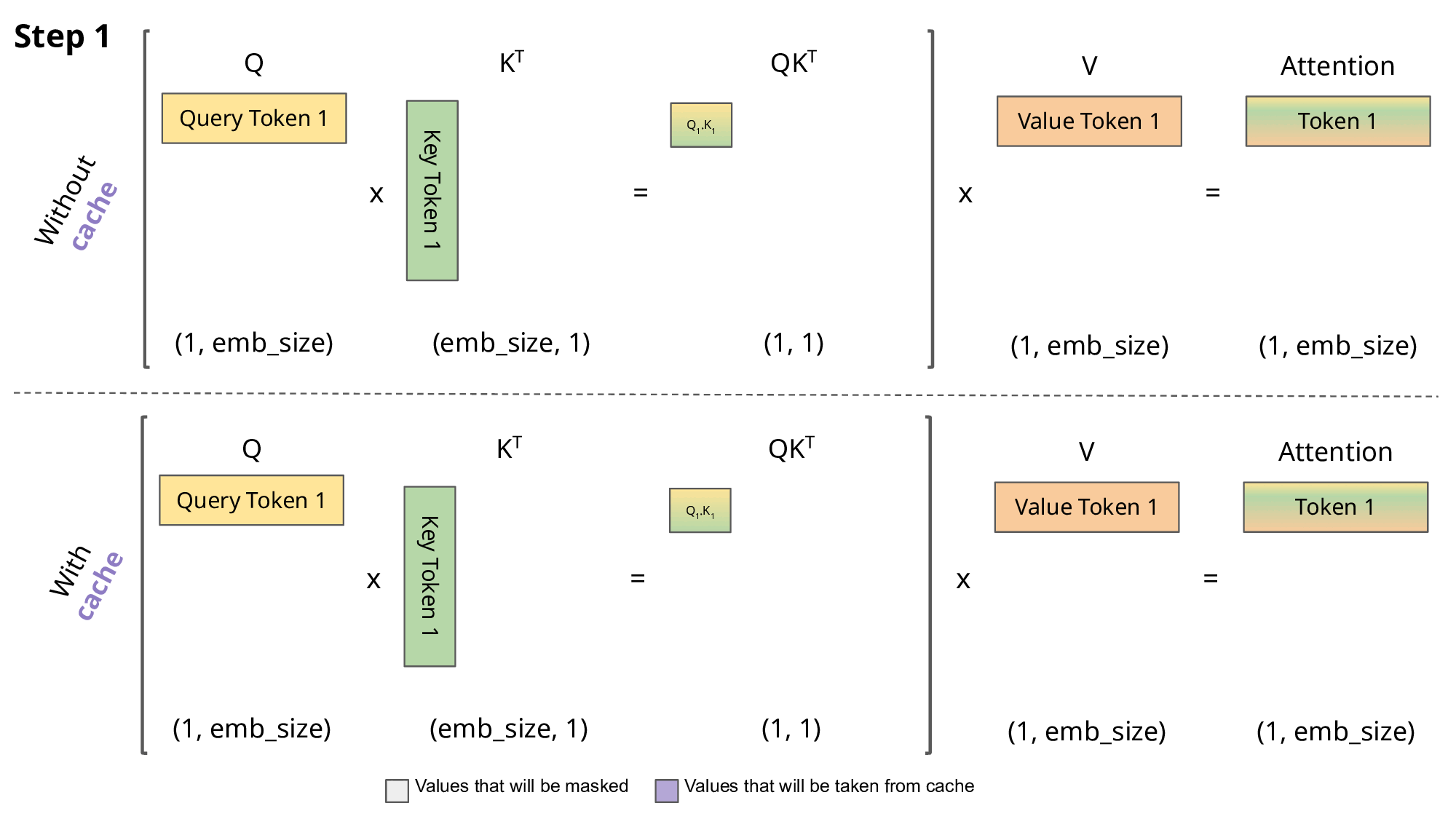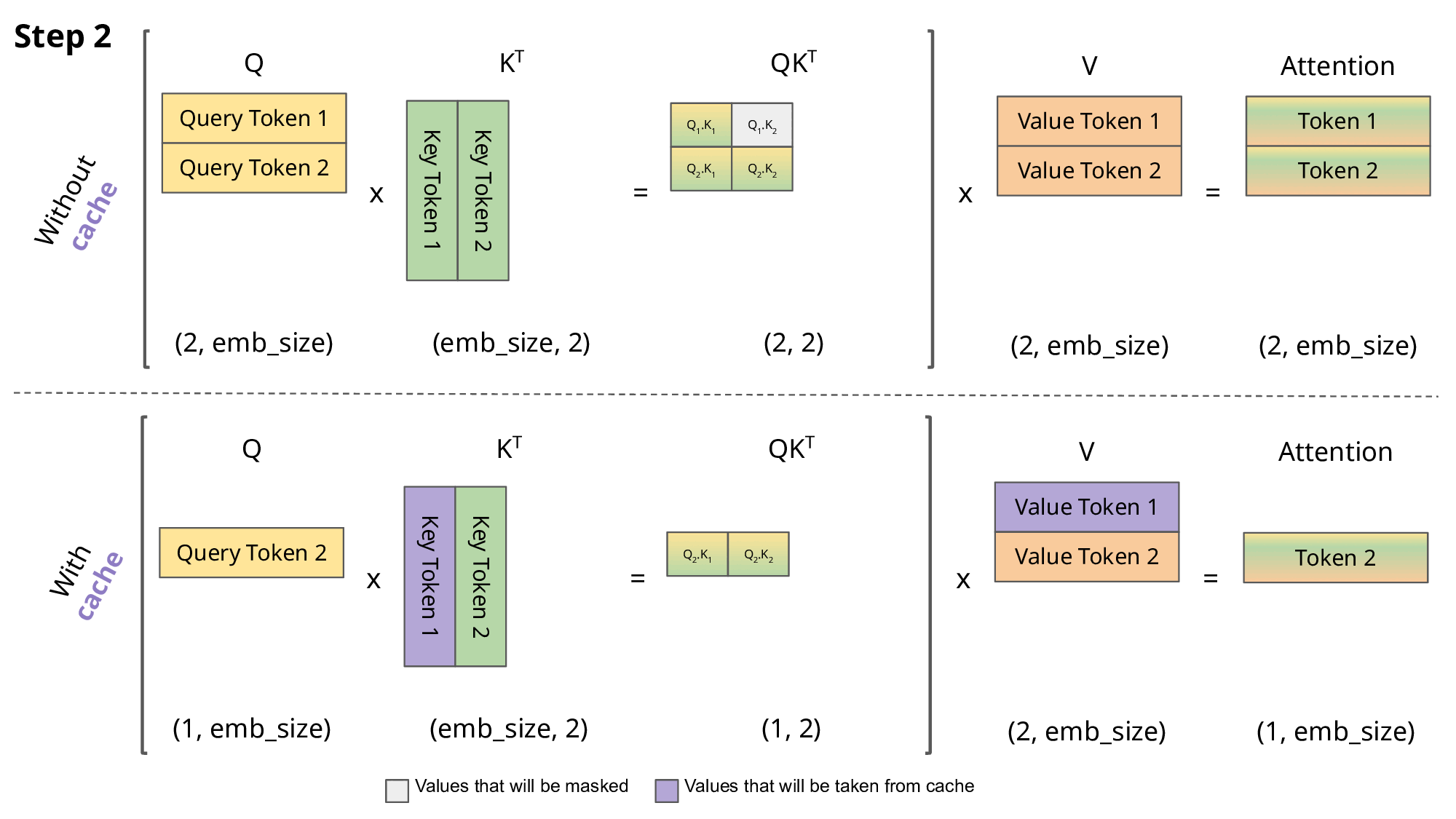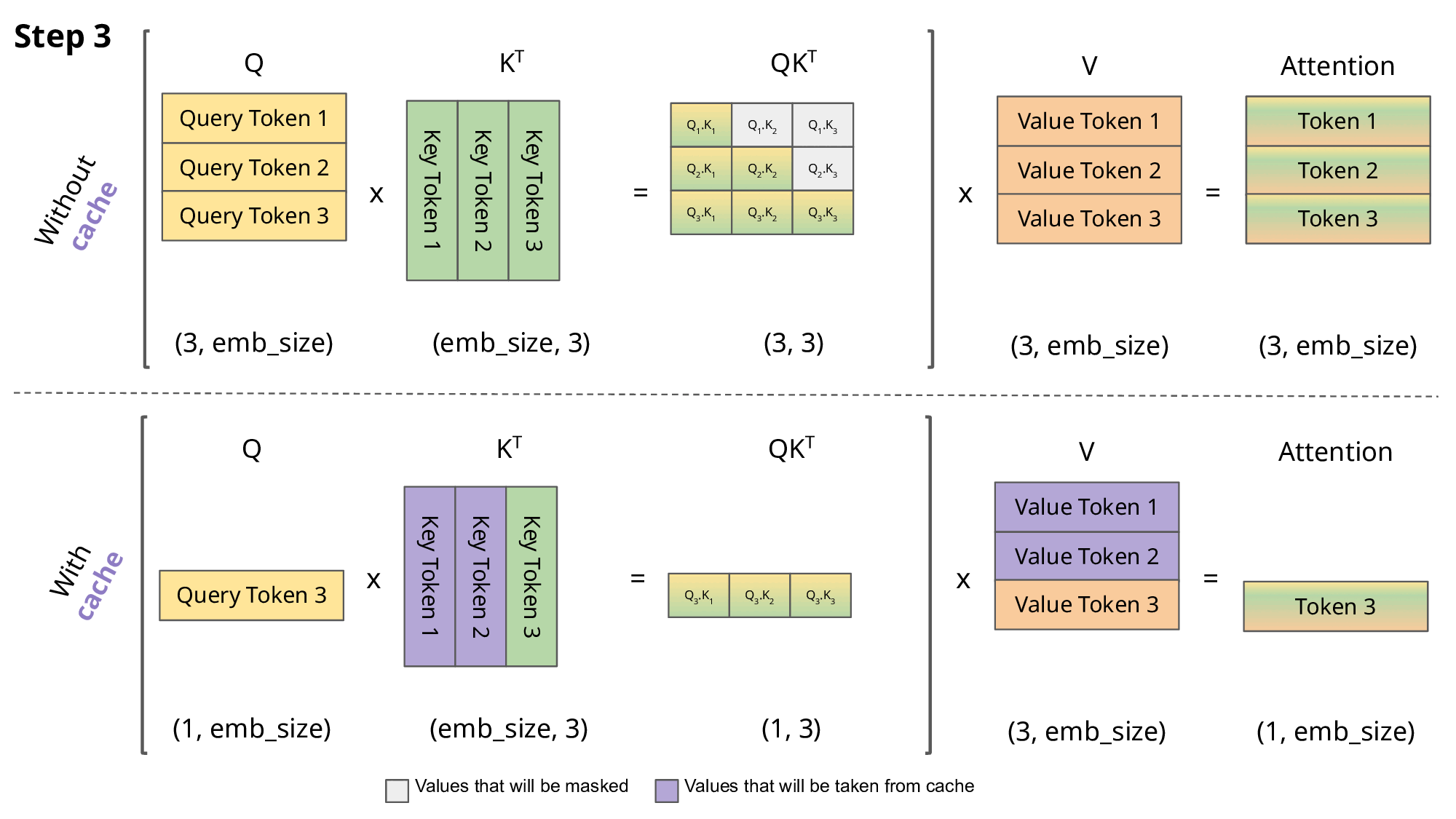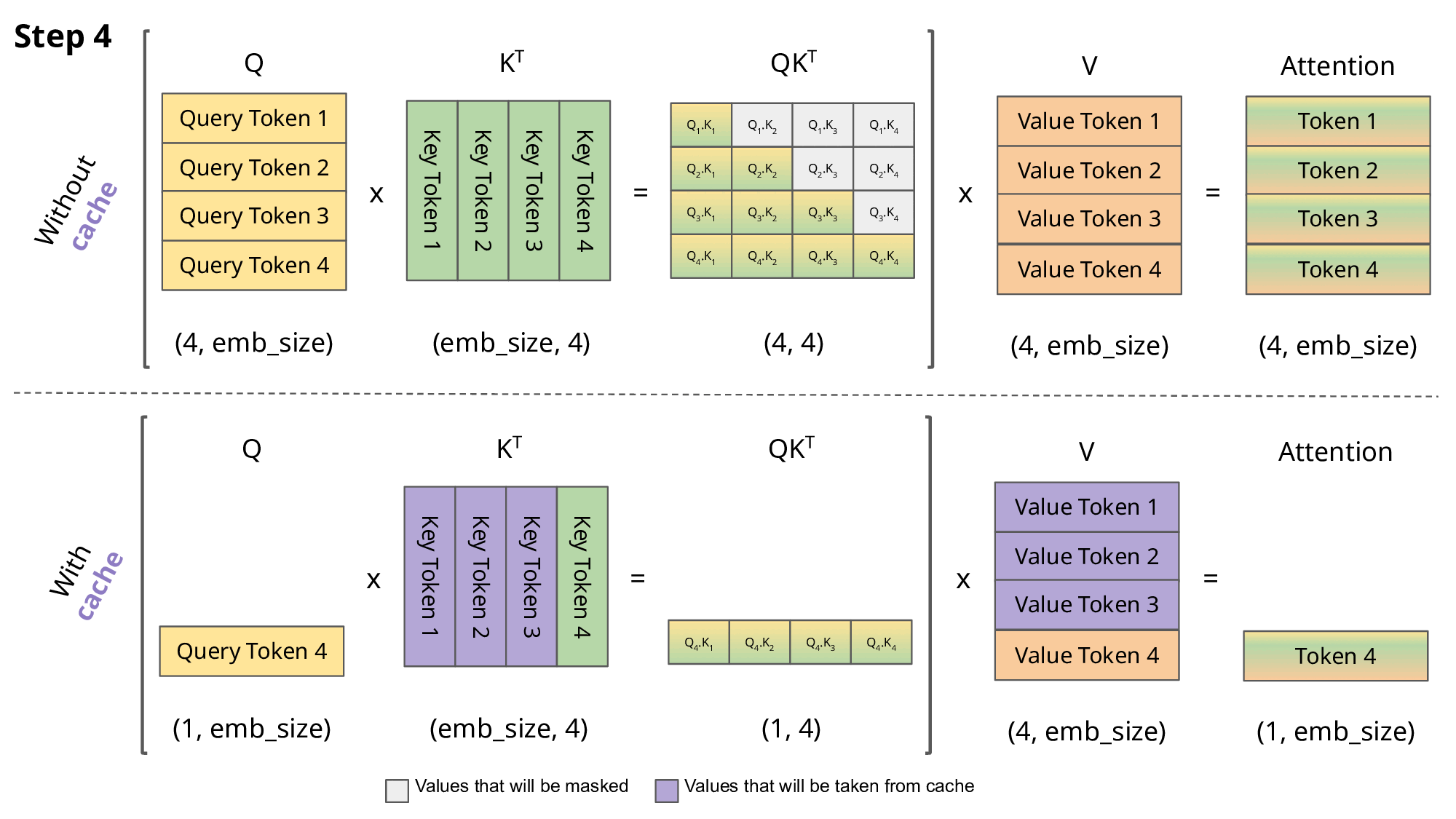
那最后一个问题,为什么叫 KVCache而不是 QKVCache 呢?
因为 Q 前面计算的结果连缓存都不用了,直接丢弃也不影响计算。
PD 分离
把推理的过程分为 Prefill(预填充)和 Decoding(解码)两个过程并不是天然产生的,是随着上面 KV cache技术的产生和对LLM应用的服务提供商SLO要求而出现的。
首先,如果没有 KV cache,prefill 和 decoding 都是将 embeddings 送到模型里面去进行一系列的矩阵运算并产生下一个token,这两个过程对于资源的要求也不会有任何差别。正是因为有了 KV cache,decoding 阶段不再需要对所有token重新进行计算,资源消耗也由计算密集型变成了内存密集型。
其次,LLM应用常常强调 TTFT(首次令牌时间)和 TPOT(每个令牌输出的时间)两个指标,对于不同类型的应用侧重可能略有不同,比如聊天机器人和总结文献,前者会两个都看重,而后者TTFT的意义就不大了。这两个指标所对应的阶段正是 Prefill 和 Decoding,所以如何提高这两个指标也变成了对这两个阶段如何进行优化。
基于这样的考虑 Distserve: Disaggregating prefill and decoding for goodputoptimized large language model serving 这篇论文提出了分离PD, 来解决上述的两个问题。
下面这张图也展示了如果将 Prefill 和 Decode 放在一个实例中会相互干扰导致吞吐率下降。
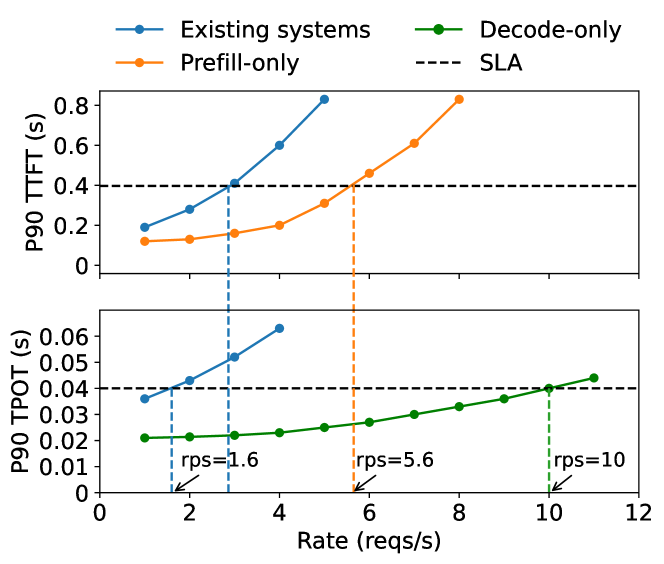
所以,只要分开就可以了?
看起来 prefill 和 decoding 相互干扰导致了吞吐量的下降,所以只要把这两个阶段分开就可以了吗?不尽然,分离PD 需要考虑的问题依然不少。
首先带来的是通信开销。以对模型 OPT-66B 一个 512-token 的请求,KV cache的大小大概是1.13GB,如果希望 rps 达到 10,那么意味着要每秒传输 11.3GB 数据,这虽然很高但是对于现在GPU集群通常配置的 800Gbps 的 InfiniBand 来说不会成为问题,节点内的A100 GPU 之间通过 NVLINK 也能达到最高 600 GB/s 的传输速率。所以通信开销大部分时候不会成为PD分离的主要问题。
其次,将1个LLM实例(instance)拆分成两个之后,并不意味着GPU的利用率或者SLO就能满足需要了,原来对LLM serving使用的一些优化策略(例如 Batching 和并行),依然需要对新的实例应用,并且由于资源需求特性的变化,策略也需要针对性地调整。
最后,更复杂的是,prefill 和 decoding 还需要根据流量、应用类型、模型大小来动态调整副本数,保证两个阶段的处理速率匹配,避免出现气泡。
对 Prefill 实例的优化
我们前面分析过,Prefill 每次处理的都是新的token序列,所以是计算密集型。因此 GPU利用率很容易达到饱和。如下所示,对于一个A100上运行的 13B 的 LLM 来说,再Prefill阶段,无论请求长度多少,基本上batch size在16的时候就无法再提高吞吐量了。
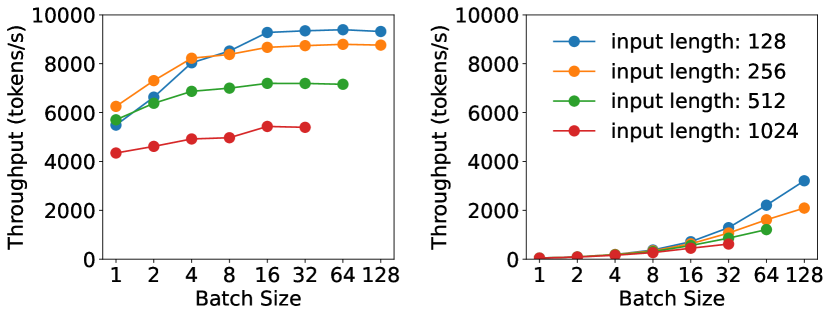
在13B大小的模型上使用不同的Batch Size时不同阶段的吞吐表现
因此对于 Prefill,需要找出对于当前 LLM 能让 GPU 饱和的最小token数,论文中以 表示。 当 达到该值后,再增加更大的Batch就没有意义了,只会增加TTFT时延。
对于并行策略的影响,作者使用 M/D/1 来建模 Prefill 阶段执行和等待时长受 inter-op(一般指PP) 和 intra-op(一般指TP)并发的加速效果。
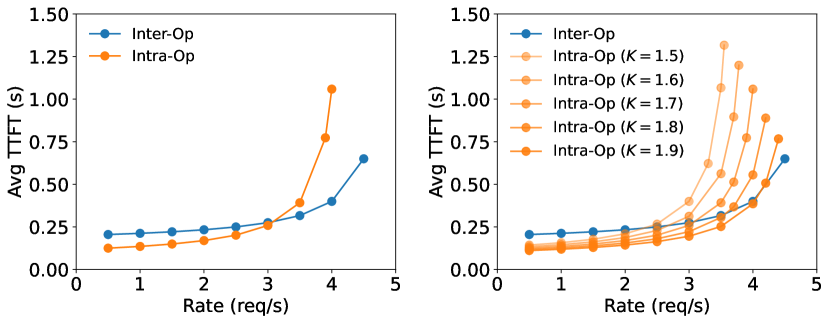
在2张A100上使用不同的并行策略部署66B的模型时平均TTFT的表现
总的来说,在低请求速率下,intra-op 对于执行时长的减小可以有效减小 TTFT,而 inter-op 增大了系统的吞吐量,使得在高请求速率下可以线性地扩展系统。这里面主要 intra-op 带来地加速效果(图中的因子K)主要受到输入长度、模型架构、通讯带宽和放置(placement,指调度拓扑)的影响。
对 Decoding 实例的优化
首先根据上图,对于解码阶段,增大batch size几乎总能线性增加吞吐率,说明 GPU 的率用率是 decoding 阶段主要的瓶颈。再增加GPU个数后,如下图所示,intra-op 可以显著降低 latency ,但由于通信成本的增加和GPU利用率的下降呈现边际递减的趋势,inter-op 则可以几乎线性地提升系统的吞吐率。
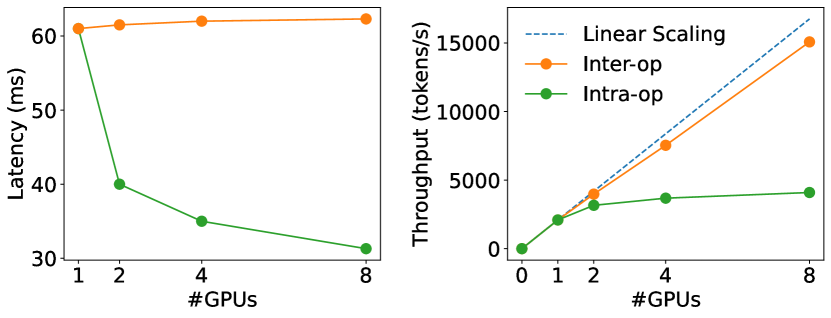
实现
基于上述的观察,论文里面设计了一种编排系统:DistServe,给定输入:
Input: LLM G, #node limit per-instance N, #GPU per-node M, GPU memory capacity C, workload W, traffic rate R.
去搜寻当前集群配置下最合适的 prefill 实例 和 decoding 实例的放置策略。希望对 DistServe 的算法和工程实现有更细节了解的,可以去查看原论文和代码。这里给出一些架构方面的参考:
The placement algorithm module implements the algorithm and the simulator mentioned in §[4] which gives the placement decision for a specific model and cluster setting. The frontend supports an OpenAI API-compatible interface where clients can specify the sampling parameters like maximum output length and temperature. The orchestration layer manages the prefill and decoding instances, responsible for request dispatching, KV cache transmission, and results delivery. It utilizes NCCL for cross-node GPU communication and asynchronous CudaMemcpy for intra-node communication, which avoids blocking the GPU computation during transmission. Each instance is powered by a parallel execution engine, which uses Ray actor to implement GPU workers that execute the LLM inference and manage the KV Cache in a distributed manner.
参考
- Transformers KV Caching Explained
- Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu,Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Distserve:Disaggregating prefill and decoding for goodputoptimized large language model serving. In Proceedings of USENIX Symposium on Operating Systems Design and Implementation, OSDI, 2024.
- Efficient memory management for large language model serving with pagedattention, 2023